What is Hadoop for Big Data Processing : Advantages and Disadvantages
Advertisement
Hadoop is an open source framework designed for storing and processing massive datasets across distributed computer clusters. It uses technologies such as HDFS and MapReduce to handle big data efficiently. Advantages include scalability and fault tolerance, while disadvantages include complex management and slower performance for real-time analytics.
What is Big Data?
“Big data” isn’t just about size; it’s about scale. The “Big” in big data refers not only to the sheer volume of data but also to the velocity at which it’s generated, the variety of its formats, and its origination from diverse sources. These are often referred to as the “Three V’s” of Big Data: Volume, Velocity, and Variety.
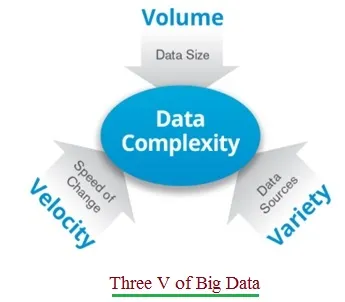 Figure-1 : Three V of Big Data
Figure-1 : Three V of Big Data
The challenges associated with big data are numerous, including capturing, curating, storing, searching, sharing, transferring, analyzing, and presenting it effectively.
Traditional computing techniques often fall short when facing these challenges, leading to the development of solutions like “Hadoop”.
What is Hadoop?
Initially, Google developed an algorithm called “MapReduce” to divide large tasks into smaller, manageable parts. These smaller tasks are then distributed across multiple computers. The processed results are then integrated to create the final dataset.
Inspired by Google’s solution, Doug Cutting and his team developed the open-source project known as Hadoop. Hadoop utilizes MapReduce (MR) algorithms, where data is processed in parallel with other datasets. This is illustrated in Figure 1.
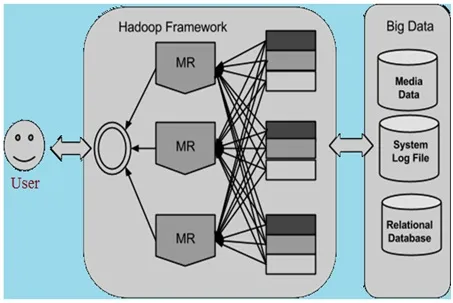 Figure-2 : Hadoop for Big Data
Figure-2 : Hadoop for Big Data
Hadoop is an Apache Open Source framework written in Java that enables the distributed processing of large datasets across clusters of computers using simple programming models.
It’s used to develop applications capable of performing comprehensive statistical analysis on vast amounts of data.
Hadoop is designed to scale from a single server to thousands of machines, providing localized computation and storage. The Hadoop architecture consists of two key layers:
- MapReduce: The Processing/Computation layer
- Hadoop Distributed File System (HDFS): The Storage layer
Advantages of Hadoop
Following are some of the benefits of Hadoop.
- Scalability: You can increase storage and computing power by simply adding more nodes to the Hadoop cluster. This eliminates the need for expensive hardware upgrades, making it a cost-effective solution.
- Handles Unstructured Data: Hadoop can effectively manage both unstructured and semi-structured data, unlike traditional databases.
- Integrated Storage and Computing: Hadoop clusters provide both storage and distributed computing capabilities in a single framework.
- Flexibility: The Hadoop framework offers built-in power and flexibility, enabling tasks that were previously impossible.
- Fault Tolerance: HDFS, the storage layer in Hadoop, has self-healing, replicating, and fault-tolerant characteristics. It automatically replicates data if a server or disk fails.
- Cost-Effective: Hadoop offers scalability, reliability, and a wide range of libraries for various applications at a relatively low cost.
- Prevents Network Overload: It distributes data across different servers, preventing network bottlenecks.
Disadvantages of Hadoop
Following are some of the limitations of Hadoop.
- Not Ideal for Small or Real-Time Data: Hadoop is not well-suited for applications that require processing small amounts of data or real-time data.
- Complex Data Joining: Joining multiple datasets can be a complex operation in Hadoop.
- Lack of Built-in Security: It does not have built-in storage or network-level encryption, requiring additional security measures.
- Cluster Management Complexity: Managing a Hadoop cluster, including tasks like debugging, distributing software, and collecting logs, can be challenging.
- Single Master Bottleneck: When operated by a single master node, scaling can become difficult.
- Restrictive Programming Model: The programming model can be restrictive for certain types of applications.
Summary
Hadoop enables distributed storage and processing of large-scale data. Advantages include scalability and reliability, while disadvantages include operational complexity and limited suitability for low-latency applications.