Hadoop Basics Tutorial: Architecture, Framework, and Benefits
Advertisement
Hadoop is an open-source framework designed to store and process intensive datasets in a distributed computing environment. It provides a scalable and cost-effective solution to handle massive amounts of data (i.e., big data) across clusters of commodity hardware.
Hadoop is primarily used for big data processing and analysis. It is a crucial technology in the field of data analytics and data-driven decision-making. Hadoop and its related projects and components have been developed under the Apache Hadoop ecosystem and are released under the Apache License, Version 2.0.
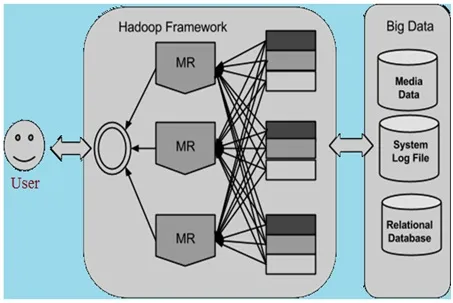
In other words, Hadoop is basically a software platform which allows one to easily write and run applications in order to process vast amounts of data. It includes:
- MapReduce - It is an offline computing engine
- HDFS - It is a Hadoop distributed file system
- HBase (pre-alpha) - It is online data access
Hadoop is used at most organizations such as Yahoo, Amazon, Facebook, Netflix, etc., which handle big data. Three main applications of Hadoop are Searches (group related documents), Advertisement, and Security (search for uncommon patterns).
Requirements of Hadoop
Following are the goals or requirements of Hadoop:
- High scalability and availability
- Abstract and facilitate the storage and processing of large and/or rapidly growing datasets (both structured and non-structured).
- Fault-tolerance
- Use commodity hardware with little redundancy
- Move computation rather than data
Hadoop Framework and Its Architecture Diagram
The framework of Hadoop consists of several core components that work together to enable distributed processing of data. It processes and analyzes massive datasets in parallel across distributed clusters of computers. The silent features of Hadoop are as follows:
- Main nodes of the cluster are where most of the computational power and storage of the system lies.
- Main nodes run TaskTracker to accept and reply to MapReduce tasks, and also DataNode to store needed blocks closely as possible.
- Distributed, with some centralization.
- Hadoop is written in Java. It also supports Ruby and Python.
- Central control node runs NameNode to keep track of HDFS directories & files, and JobTracker to dispatch compute tasks to TaskTracker.
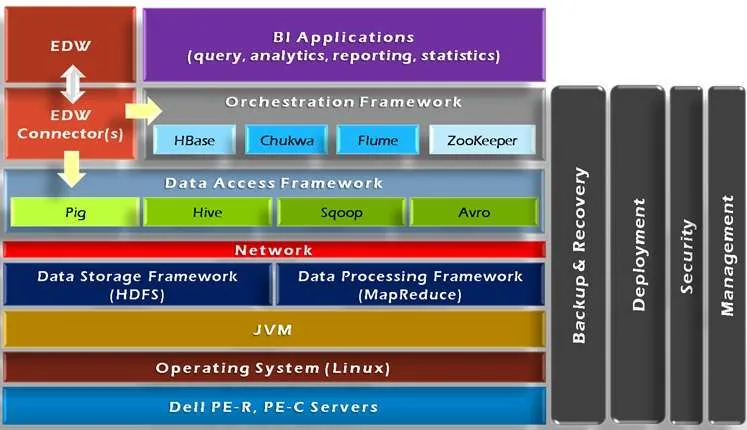
Let us understand components shown in the Hadoop framework diagram.
- HDFS (Hadoop Distributed File System): It is a distributed file system which stores data across multiple machines. It is designed for high throughput and can handle petabytes of data.
- MapReduce: It is a programming model and processing engine used to process and analyze large datasets in parallel.
- YARN: It is a resource management layer of Hadoop. It manages and allocates resources such as CPU, memory, etc., to different applications running on the cluster.
- Hadoop Common: It contains libraries and utilities which are shared across various Hadoop components.
- Hadoop Eco-System: Hadoop has a rich ecosystem of related projects which include Apache Hive, Apache Spark, Apache HBase, Apache Sqoop, Apache Flume, etc.
Benefits of Hadoop
Following are the advantages or benefits of Hadoop.
- It allows us to scale data processing infrastructure by adding more machines to the cluster as data under analysis grows.
- HDFS (Hadoop Distributed File System) breaks large files into smaller blocks and stores them across multiple machines in the cluster. It ensures high data availability and fault tolerance.
- Hadoop’s MapReduce model enables parallel processing of data.
- Hadoop can run on commodity hardware which is cheaper compared to high-end expensive servers.
- The architecture of Hadoop supports various data types, formats, and sources.
- Hadoop extends its capabilities through various projects and tools for data ingestion, data warehousing, data processing, real-time analytics, machine learning, and more.
- It can process data where it is stored and hence reduces the need for data movement.
- Its distributed nature ensures that data and processing can continue on other nodes even if any one node fails.
- It enables real-time and stream processing which allows organizations to process and analyze data as it arrives.
Conclusion
Hadoop is developed and maintained by a vibrant open-source community. Hence, the Hadoop framework offers continuous improvements, bug fixes, and the availability of a wealth of resources and tools.